Google has already that crawling, on its own, doesn't affect your website's ranking.
Some SEO experts might disregard the crawl budget due to this.
But, but, but…that is not the right practice here. Well, tell us one thing…
If your content is not discoverable, what’s the point of even posting it?
Furthermore, Google's Gary Illyes acknowledges that managing a crawl budget is sensible for large websites with millions of pages.
In fact, if your site has an excessive number of pages, consider trimming some content, which can benefit your overall domain.
SEO involves making numerous small, incremental improvements and optimizing various metrics.
It's about ensuring thousands of small elements are as optimized as possible.
In light of this, it's crucial to ensure nothing on your website is negatively impacting your crawl budget.
What Is Crawl Budget?
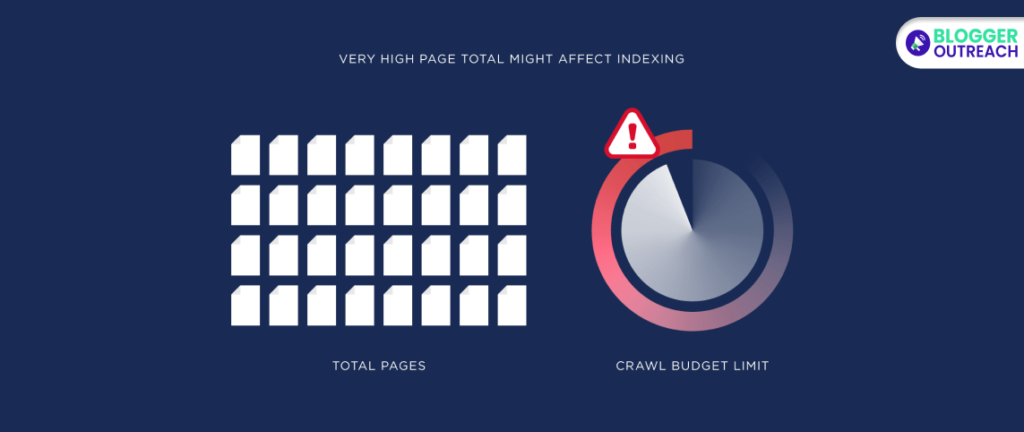
Crawl budget refers to the amount of time and resources Google invests in crawling your site.
(Crawling is when a search engine sends bots to read new or updated pages to Google.)
A crawl budget is like a website's snack allowance for search engines. Search engines send out little programs called "crawlers" to explore your site. These crawlers follow links, visit pages, and collect info for search engine indexes.
Think of it as a daily budget of pages your site can show to these crawlers. If you have a small site, this budget isn't a big deal. But for large websites, it matters.
Search engines decide your crawl budget based on your site's quality and importance. They focus on the more crucial pages, so ensure your important stuff is easily accessible.
How does Google determine the crawl budget?
Basically, There Are Two Factors Responsible For Crawling:
- Crawl capacity limit.
- Crawl demand.
1. Crawl Capacity Limit
Googlebot aims to crawl your website without straining your servers. To achieve this, Googlebot determines a crawl capacity limit.
It represents the highest number of simultaneous connections it can use to explore your site, along with the time gap between fetches.
This calculation ensures that it covers your essential content without causing server overload.
- Crawl Health: If your site consistently responds quickly, the limit increases, allowing for more simultaneous connections. However, if your site experiences slowdowns or server errors, the limit decreases, and Googlebot crawls less.
- Owner-Set Limits In Search Console: Website owners can reduce Googlebot's crawling activities on their site. Remember that setting higher limits won't automatically lead to increased crawling.
- Google's Crawling Resources: While Google has numerous machines at its disposal, they are not limitless. Decisions regarding resource allocation must be made with the available resources in mind.
2. Crawl Demand
Crawl demand is what your site wants them to see. If demand exceeds capacity, some pages may get left out.
Google ensures it invests the necessary time in crawling a website, considering factors like its:
- Size
- Update frequency
- Page Quality
- Relevance compared to other sites
Several Essential Elements Influence Crawl Demand:
- Perceived Inventory: Without your guidance, Googlebot attempts to crawl most of the known URLs on your site. Google crawls URLs that are duplicates or can't be crawled (removed or unimportant), wasting valuable crawling time. You have the most control over this factor.
- Popularity: URLs with higher popularity on the Internet receive more frequent crawling to maintain their freshness in Google's index.
- Staleness: Google's systems aim to recrawl documents often enough to capture any updates or changes.
Additionally, events such as site moves may lead to an increased crawl demand to reindex content.
Quick Impact Crawl Budget Optimization Strategy

An effective crawl budget optimization strategy ensures your content gets optimum exposure.
1. Manage Your URL inventory
To kickstart your crawl budget optimization strategy, you must manage your URL inventory effectively.
Use the appropriate tools to inform Google about which pages to crawl and which ones to skip.
It's crucial to ensure that Google doesn't waste precious crawl time on pages that aren't valuable for indexing.
If Googlebot spends too much time on irrelevant URLs, it may decide that it's not worth exploring the rest of your site or increasing the crawl budget allocated to it.
2. Consolidate Duplicate Content
One common issue that can hamper your crawl budget is duplicate content.
When search engines encounter duplicate content across your website, they may waste crawl resources on identical information.
To optimize your crawl budget, focus on eliminating duplicate content.
By doing so, you'll encourage search engines to concentrate on crawling unique and valuable content…
…rather than repeatedly crawling the same information under different URLs.
3. Block Crawling Of URLs Using Robots.txt
Sometimes, you may have pages on your website that are essential for users but not necessarily for search results. Pages with infinite scrolling or different sorted versions of the same page are examples...
If you can't consolidate these pages, as mentioned previously, consider blocking them using the robots.txt file. Blocking URLs with robots.txt significantly reduces the chances of them being indexed.
However, remember not to use the "noindex" directive. Because it can waste crawl time as…
…Google will still request and then drop the page when it encounters a noindex meta tag or header in the HTTP response.
Use robots.txt to block pages or resources that you don't want Google to crawl at all. Google won't reallocate this new crawl budget to other pages unless it hits your site's serving limit.
4. Return A 404 Or 410 Status Code For Permanently Removed Pages
When you decide to remove a page permanently, it's crucial to communicate this clearly to search engines. Google won't forget a URL that it knows about, but 404 or 410 status codes indicate the page shouldn't be crawled again.
Blocked URLs, however, will remain in your crawl queue for a longer time and will be recrawled when the block is removed. To maximize your crawl budget, ensure that you return the appropriate status codes for removed pages.
5. Eliminate Soft 404 Errors
Soft 404 errors can be a thorn in your crawl budget optimization strategy. Pages categorized as 404 errors will continue to be crawled, consuming your budget unnecessarily. Regularly check the Index Coverage report for soft 404 errors. Then, address them promptly to prevent wasteful crawling.
6. Keep Your Sitemaps Up To Date
Google regularly reads your sitemap to understand the structure of your website. To optimize your crawl budget, make sure to keep your sitemaps up to date.
Include all the content that you want Google to crawl, and if your site features updated content, use the "<lastmod>" tag to indicate the last modification date.
This helps Google understand when to revisit your pages, making your crawl budget allocation more efficient.
7. Avoid Long Redirect Chains
Long redirect chains can negatively impact crawling efficiency. When a search engine encounters a series of redirects, it must follow each one, consuming valuable crawl resources.
To optimize your crawl budget, minimize redirect chains and ensure that they are as short as possible. This will allow search engines to spend more time actually crawling and indexing your content.
8. Make Your Pages Efficient To Load
The speed at which your web pages load can influence your crawl budget. Google can read more content from your site if it loads and renders your pages quickly.
Therefore, optimize your website's speed and performance to make the most of your crawl budget.
9. Monitor Your Site Crawling
Regularly monitor your website's crawling performance. Check for any availability issues during crawling and look for ways to make the process more efficient.
Stay vigilant and address issues promptly. This way, you can ensure that your crawl budget is put to good use.
Frequently Asked Questions (FAQs):
To clarify, we have compiled the list from Google’s official document. Here you go:
A: Making a site faster improves the user's experience while also increasing the crawl rate. For Googlebot, a speedy site is a sign of healthy servers, so it can get more content over the same number of connections. On the flip side, a significant number of 5xx errors or connection timeouts signal the opposite, and crawling slows down.
We recommend paying attention to the Crawl Errors report in the Search Console and keeping the number of server errors low.
A: An increased crawl rate will not necessarily lead to better positions in Search results. Google uses hundreds of signals to rank the results, and while crawling is necessary for being in the results, it's not a ranking signal.
A: Generally, any URL that Googlebot crawls will count towards a site's crawl budget. Alternate URLs, like AMP or hreflang, as well as embedded content, such as CSS and JavaScript, including AJAX (like XHR) calls, may have to be crawled and will consume a site's crawl budget. Similarly, long redirect chains may have a negative effect on crawling.
A: The non-standard crawl-delay robots.txt rule is not processed by Googlebot.
A: It depends. Any URL that is crawled affects the crawl budget, so even if your page marks a URL as nofollow it can still be crawled if another page on your site, or any page on the web, doesn't label the link as nofollow.
A: No, disallowed URLs do not affect the crawl budget.”
The Closing Statement
Before we wrap up, our stance is very clear.
The crawl budget is crucial. Just because it isn’t directly related to ranking, that doesn’t mean you overlook it.
Well, that’s for the day.
If you have further doubts, feel free to reach out!
Read Also: